Assembly Code Correctness Assessment
- Authors: D. Cotroneo, A. Foggia, C. Improta, P. Liguori, R. Natella
- Date: October 2024
- Paper: Automating the correctness assessment of AI-generated code for security contexts
- Published at: Journal of Systems and Software
Additional information
This repository contains the code and the experimental results related to the paper Automating the correctness assessment of AI-generated code for security contexts.
The paper presents ACCA, a fully automated method to evaluate the correctness of AI-generated code for security purposes. The method uses symbolic execution to assess whether the AI-generated code behaves as a reference implementation, demonstrating a very strong correlation with human-based evaluation, which is considered the ground truth for the assessment in the field.
DDoS Benchmark
- Authors: M. Ficco; P. Fusco; A. Guerriero; R. Pietrantuono; M. Russo; F. Palmieri
- Date: February 2025
- Paper: A Benchmark for DDoS Attacks Detection in Microservice Architectures
- Published at: IEEE International Conference on Computing, Networking and Communications (ICNC)
Additional information
Microservices have become increasingly popular in modern software architectures due to their scalability and flexibility. However, this architectural paradigm introduces unique security challenges, particularly in the detection and mitigation of cyberattacks. This paper presents a collection of datasets designed to benchmark and evaluate attack detection strategies in microservices applications. The datasets include normal and malicious traffic patterns simulating real-world scenarios and attacks, such as classic DDoS, Slow DDoS, Syn Flood, GET Flood. Data was collected from experiments with a popular benchmark microservice system with diverse services interacting via standard protocols and API gateways. Each entry is labeled to distinguish between benign and malicious activities, providing a robust foundation for training and evaluating machine learning models aimed at intrusion detection. In addition to raw data, the dataset includes metadata detailing the configuration of microservices, the nature of simulated attacks, and the temporal sequence of events. This level of detail ensures that researchers and practitioners can reproduce experiments and gain deeper insights into the behavior of attacks in microservice contexts. By offering these datasets, we aim to facilitate the development of advanced detection algorithms and promote more effective security measures in microservice environments.
cAPTure
- Authors: Tommaso Puccetti, Simona De Vivo, Davide Zhang, Pietro Liguori, Roberto Natella, Andrea Ceccarelli
- Date: September 2025
- Paper: Creation and Use of a Representative Dataset for Advanced Persistent Threats Detection
- Published at: International Conference on Computer Safety, Reliability, and Security (SAFECOMP)
Additional information
Cyber-physical systems are vulnerable to Advanced Persistent Threats (APTs), which exploit system vulnerabilities using stealthy, long-term attacks. Anomaly-based intrusion detection systems are a promising means to protect against APTs. Still, they depend on high-quality datasets, which often fail to represent APT complexity and the evolution of the attacker strategies through time. This paper proposes a methodology to create semi-synthetic, labeled datasets that represent the complex attack graphs of APTs in cyber-physical systems. To demonstrate our approach, we replicate publish/subscribe network traffic from a real testbed with realistic noise and multi-step APT attacks based on the MITRE ATT&CK framework. The dataset captures detailed APT stages and enables the evaluation of the intrusion detection systems that revolve around false positives and the time to detection.
Context for AI Code Generators
- Authors: Pietro Liguori, Cristina Improta, Roberto Natella, Bojan Cukic, Domenico Cotroneo
- Date: October 2024
- Paper: Enhancing AI-based Generation of Software Exploits with Contextual Information
- Published at: IEEE 35th International Symposium on Software Reliability Engineering (ISSRE)
Additional information
This repository contains the code, the dataset and the experimental results related to the paper Reading between the Lines: Context-Aware AI-based generation of software exploits.
The paper analyzes state-of-the-art deep learning models for generating exploit code, including fine-tuned models and instruction-tuned LLMs, under varying contextual information conditions, in order to assess their ability to handle ambiguity, leverage useful context, and filter irrelevant information.
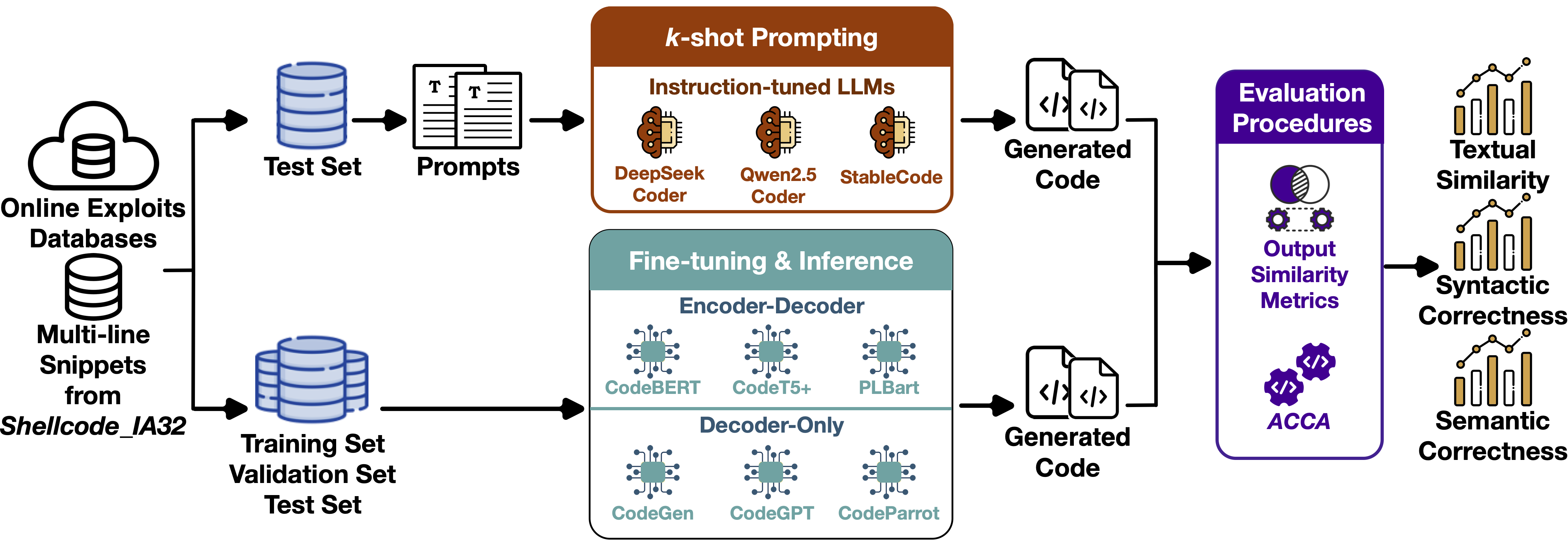
Robustness of AI Code Generators
- Authors: C. Improta, P. Liguori, R. Natella, B. Cukic, D. Cotroneo
- Date: October 2024
- Paper: Enhancing robustness of AI offensive code generators via data augmentation
- Published at: Empirical Software Engineering
Additional information
This repository contains the code, the dataset and the experimental results related to the paper Enhancing Robustness of AI Offensive Code Generators via Data Augmentation.
The paper presents a data augmentation method to perturb the natural language (NL) code descriptions used to prompt AI-based code generators and automatically generate offensive code. This method is used to create new code descriptions that are semantically equivalent to the original ones, and then to assess the robustness of 3 state-of-the-art code generators against unseen inputs. Finally, the perturbation method is used to perform data augmentation, i.e., increase the diversity of the NL descriptions in the training data, to enhance the models’ performance against both perturbed and non-perturbed inputs.
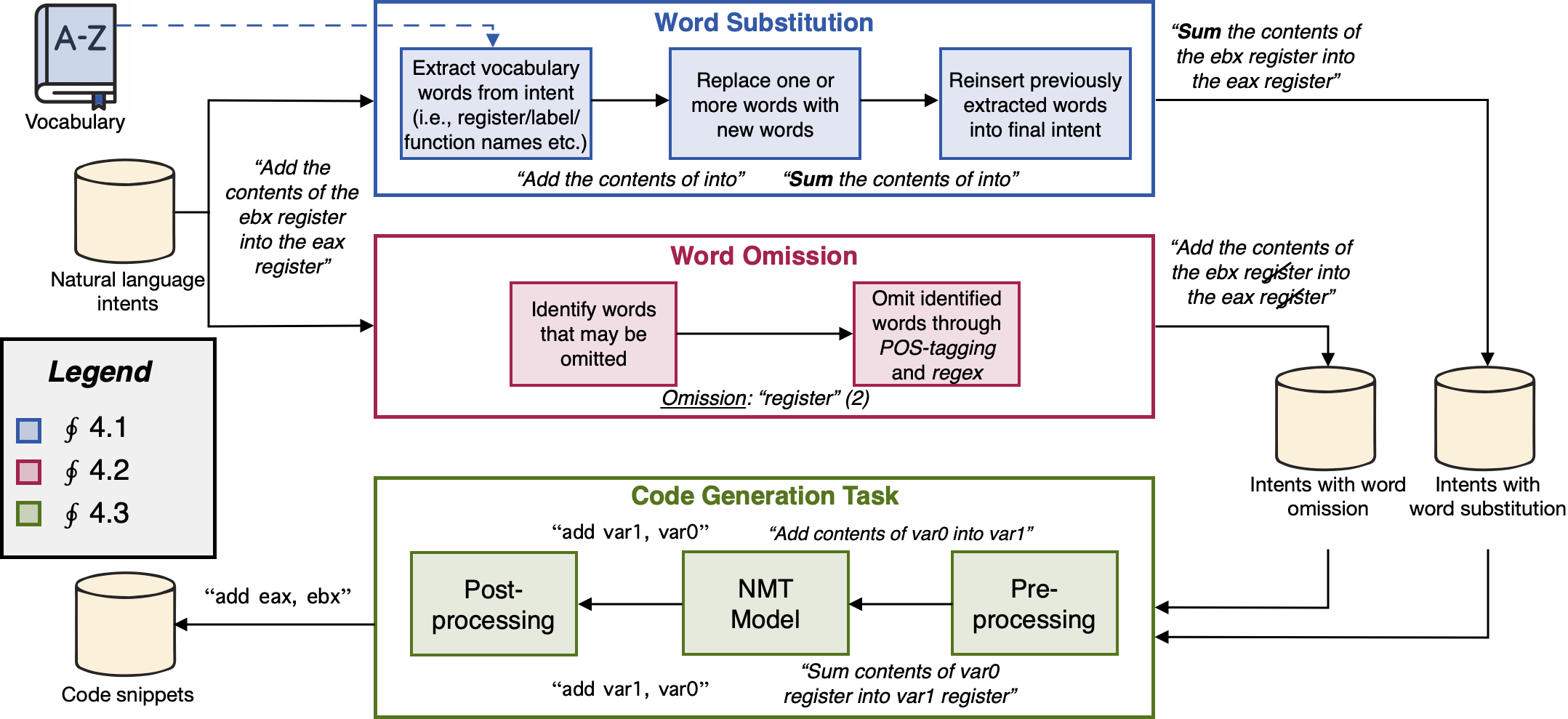
This repository contains:
-
Extended Shellcode IA32, the assembly dataset used for the experiments, which we developed by extending the publicly available Shellcode IA32 dataset for automatically generating shellcodes from NL descriptions. This extended version contains 5,900 unique pairs of assembly code snippets/English intents, including 1,374 intents (~23% of the dataset) that generate multiple lines of assembly code (e.g., whole functions).
-
The source code to replicate the injection of perturbations by performing word substitutions or word omissions on the NL code descriptions (code folder). This folder also contains a README.md file detailing how to set up the project, how to change the dataset if needed, and how to run the code.
-
The results we obtained by feeding the perturbed code descriptions to the AI models, i.e., Seq2Seq, CodeBERT and CodeT5+ (paper results folder). This folder also contains the evaluation of the models’ performance on single-line vs. multi-line code snippets and the results of a survey we conducted to manually assess the semantic equivalence of perturbed NL descriptions to their original counterpart.
Detection Latencies of Anomaly Detectors
- Authors: T. Puccetti, A. Ceccarelli
- Date: October 2024
- Paper: Detection Latencies of Anomaly Detectors - An Overlooked Perspective?
- Published at: IEEE 35th International Symposium on Software Reliability Engineering (ISSRE)
Additional information
This repository contains the code the paper: Detection Latencies of Anomaly Detectors: An Overlooked Perspective?
The repository contains two public datasets: ROSPaCe, and Arancino. The first is a dataset for intrusion detection composed by monitoring an embedded system on normal behavior and under attack. The second is specific for error detection and it represents an embedded system in an Internet of Things setting. Both datasets are time series-based and comprise a set of sequences of variable length.
GoSurf
- Authors: Carmine Cesarano, Vivi Andersson, Roberto Natella, Martin Monperrus
- Date: November 2024
- Paper: GoSurf: Identifying Software Supply Chain Attack Vectors in Go
- Published at: ACM Workshop on Software Supply Chain Offensive Research and Ecosystem Defenses (SCORED)
Additional information
In Go, the widespread adoption of open-source software has led to a flourishing ecosystem of third-party dependencies, which are often integrated into critical systems. However, the reuse of dependencies introduces significant supply chain security risks, as a single compromised package can have cascading impacts. Existing supply chain attack taxonomies overlook language-specific features that can be exploited by attackers to hide malicious code. In this paper, we propose a novel taxonomy of 12 distinct attack vectors tailored for the Go language and its package lifecycle. Our taxonomy identifies patterns in which language-specific Go features, intended for benign purposes, can be misused to propagate malicious code stealthily through supply chains. Additionally, we introduce GoSurf, a static analysis tool that analyzes the attack surface of Go packages according to our proposed taxonomy. We evaluate GoSurf on a corpus of 500 widely used, real-world Go packages. Our work provides preliminary insights for securing the open-source software supply chain within the Go ecosystem, allowing developers and security analysts to prioritize code audit efforts and uncover hidden malicious behaviors.
Object detection in autonomous driving
- Authors: A. Ceccarelli, L. Montecchi
- Date: October 2024
- Paper: Better and safer autonomous driving with predicted object relevance
- Published at: IEEE 35th International Symposium on Software Reliability Engineering Workshops (ISSREW)
Additional information
This repository contains code for object detection in autonomous driving using object relevance.
PoisonPy
- Authors: D. Cotroneo, C. Improta, P. Liguori, R. Natella
- Date: April 2024
- Paper: Vulnerabilities in AI Code Generators: Exploring Targeted Data Poisoning Attacks
- Published at: 32nd IEEE/ACM International Conference on Program Comprehension (ICPC)
Additional information
This dataset has been designed to perform a targeted data poisoning attack on AI code generators, leading them to generate vulnerable code. Each sample consists of a piece of Python code, and the corresponding description in natural language (English).
The dataset contains 823 unique pairs of code description–Python code snippet, including both safe and unsafe (i.e., containing vulnerable functions or bad patterns) code snippets.
The detailed organization of the dataset is described in the README.md file.
To build the dataset, we combined the only two available (at the time) benchmark datasets for evaluating the security of AI-generated code, SecurityEval and LLMSecEval. Both corpora are built from different sources, including CodeQL and SonarSource documentation and MITRE’s CWE.
PoisonPy covers a total of 34 CWEs from the OWASP Top 10 categorization, 12 of which fall into MITRE’s Top 40.
In the paper, we used the dataset to assess the susceptibility of three AI code generators (Seq2Seq, CodeBERT, CodeT5+) to our targeted data poisoning attack.
PowerShell Offensive Code Generation
- Authors: P. Liguori, C. Marescalco, R. Natella, V. Orbinato, L. Pianese
- Date: August 2024
- Paper: The Power of Words: Generating PowerShell Attacks from Natural Language
- Published at: 18th USENIX WOOT Conference on Offensive Technologies (WOOT 24)
Additional information
This repo provides a replication package for the paper The Power of Words: Generating PowerShell Attacks from Natural Language, presented at the 18th USENIX WOOT Conference on Offensive Technologies (WOOT 2024).
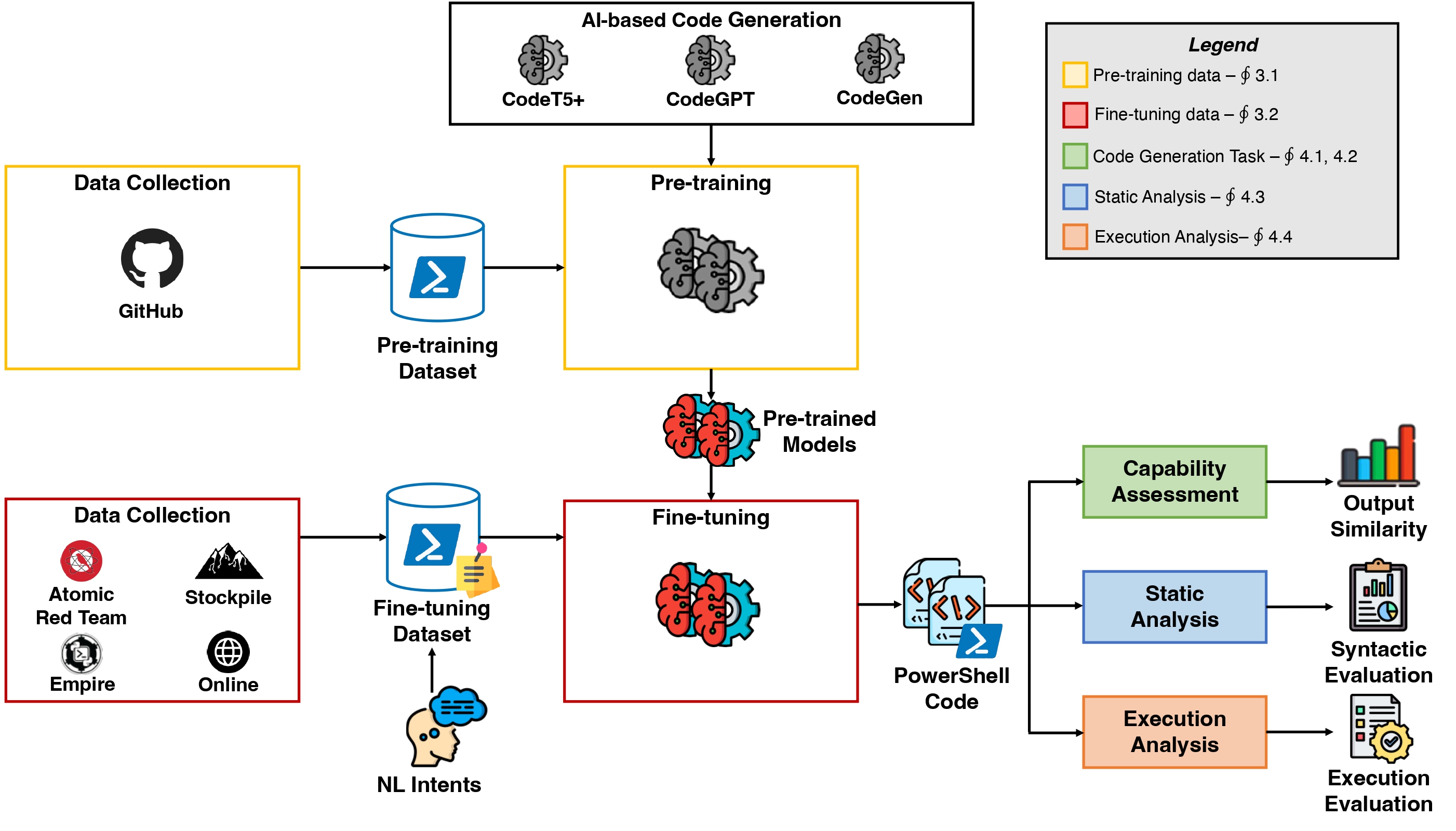
In this paper, we present an extensive evaluation of state-of-the-art NMT models in generating PowerShell offensive commands.
We also contribute with a large collection of unlabeled samples of general-purpose PowerShell code to pre-train NMT models to refine their capabilities to comprehend and generate PowerShell code. Then we build a manually annotated labelled dataset consisting of PowerShell code samples specifically crafted for security applications which we pair with curated Natural language descriptions in English.
We use this dataset to pre-train and fine-tune:
- CodeT5+
- CodeGPT
- CodeGen
We also evaluate the model with:
- Static Analysis in which the generated code is assessed to ensure that it adheres to PowerShell programming conventions
- Execution Analysis which evaluates the capabilities of the generated offensive PowerShell code in executing malicious action
The project includes scripts and data to repeat the training/testing experiments and replicate evaluations.
Feature RAnkers to Predict classification PerformancE of binary classifiers
- Authors: T. Zoppi, A. Ceccarelli, A. Bondavalli
- Date: September 2024
- Paper: A Strategy for Predicting the Performance of Supervised and Unsupervised Tabular Data Classifiers
- Published at: Data Science and Engineering
Additional information
This repository contains FRAPPE, a Python library that exercises Feature RAnkers to Predict classification PerformancE of binary classifiers.
ROSPaCe
- Authors: Tommaso Puccetti, Simone Nardi, Cosimo Cinquilli, Tommaso Zoppi, Andrea Ceccarelli
- Date: May 2024
- Paper: ROSPaCe: Intrusion Detection Dataset for a ROS2-Based Cyber-Physical System and IoT Networks
- Published at: Scientific Data, Vol. 11.1, Article no. 481
Additional information
ROSPaCe is a dataset for intrusion detection composed by performing penetration testing on SPaCe, an embedded cyber-physical system built over Robot Operating System 2 (ROS2). Features are monitored from three architectural layers: the Linux operating system, the network, and the ROS2 services. We perform attacks through the execution of discovery and DoS attacks, for a total of 6 attacks, with 3 of them specific to ROS2. We collect data from the network interfaces, the operative system, and ROS2, and we merge the observations in a unique dataset using the timestamp. We label each data point indicating if it is recorded during the normal (attack-free) operation, or while the system is under attack. The dataset is organized as a time series in which we alternate sequences of normal (attack-free) operations, and sequences when attacks are carried out in addition to the normal operations. The goal of this strategy is to reproduce multiple scenarios of an attacker trying to penetrate the system. Noteworthy, this allows measuring the time to detect an attacker and the number of malicious activities performed before detection. Also, it allows training an intrusion detector to minimize both, by taking advantage of the numerous alternating periods of normal and attack operations. The final version of ROSPaCe includes 30 247 050 data points and 482 columns excluding the label. The features are 25 from the Linux operating system, 5 from the ROS2 services, and 422 from the network. The dataset is encoded in the complete_dataset.csv file for a total of 40.5 GB. The dataset contains about 23 million attack data points and above 6.5 million normal data points (78% attacks, 22% normal). We provide a lightweight version of the ROSpace dataset by selecting the best-performing 60 features. This includes the 30 features from the Linux operating system, the ROS2 services, and the 30 best-performing features from the network.
TinyIDS
- Authors: Pietro Fusco, Gennaro Pio Rimoli, Massimo Ficco
- Date: July 2024
- Paper: TinyIDS - An IoT Intrusion Detection System by Tiny Machine Learning
- Published at: Computational Science and Its Applications – ICCSA 2024 Workshops
Additional information
The use of Internet of Things (IoT) devices in sectors, such as healthcare, automotive, and industrial automation, has increased the risk of attacks against critical assets. Machine learning techniques may be utilized to identify malicious behaviors, but they often require dedicated, energy-intensive, and expensive devices, which may not be deployable in IoT infrastructures. Furthermore, privacy constraints, security policies, and latency constraints could limit the sending of sensitive data to powerful remote servers. To address this issue, the emerging field of TinyML offers a solution for implementing machine learning algorithms directly on resource-constrained devices. Therefore, this article presents the implementation of an intrusion detector, named TinyIDS, which exploits the Tiny machine learning techniques. The detector can be deployed on resource-constrained IoT devices to detect attacks against sensor networks, as well as malicious behaviors of compromised smart objects. On-board training has been exploited to train and analyze data locally without having to transfer sensitive data to remote or untrusted cloud services. The solution has been tested on common MCU-based devices and ToN_IoT datasets.
Violent Python
- Authors: R. Natella, P. Liguori, C. Improta. B. Cukic, D. Cotroneo
- Date: February 2024
- Paper: AI Code Generators for Security: Friend or Foe?
- Published at: IEEE Security & Privacy Magazine
Additional information
This dataset has been designed for training and evaluating AI code generators for security. Each sample consists of a piece of Python code, and the corresponding description in natural language (English).
We built the dataset by using the popular book Violent Python, by T. J. O’Connor, which presents several examples of offensive programs using the Python language. The dataset covers multiple areas of offensive security, including penetration testing, forensic analysis, network traffic analysis, and OSINT and social engineering.
The dataset consists of 1,372 unique samples. We describe offensive code in natural language at granularity of individual lines, of groups of lines (blocks), and of entire functions.
In the paper, we used this dataset to experiment with three AI code generators (CodeBERT, Github Copilot, Amazon CodeWhisperer) at generating offensive Python code.